习题答案:https://github.com/changkun/modern-cpp-tutorial/tree/master/exercises
序言
本文传统C++ 是指C++ 98及之前的标准。
C++ 14/17是对C++ 11的重要补充和优化;而C++ 20则将这门语言领进了现代化的大门。
关于一些特性的初探:
- auto关键字语义给操纵极为复杂的模板类型提供了底层支持;
- lambda表达式基于C++匿名函数的闭包特性;
- 右值引用的出现解决了C++长期被人诟病的临时对象效率问题;
第一章迈向现代C++
被弃用的特性
弃用并非不能用,只是暗示这些特性将从未来的标准消失。
- 不允许使用字符串面值常量赋值给char *,如果使用应该是用const char**或者auto。
- C++98异常说明、unexpected_handler, set_unexpected()等特性被弃用,应该使用noexcept。
- auto_ptr被弃用,用使用unique_ptr。
- register关键词被弃用。
- bool类型的++操作被弃用
- 如果一个类有析构函数,为其生成拷贝构造函数和拷贝复制运算符的特性被弃用了。
- C风格的类型转换被弃用了(即在变量前是用(convert_type)),应该使用static_cast、reinterpret_cast、const_cast来进行类型转换。
- ……等等
与C的兼容
C++不是C的一个超集。
用extern "C"特性时,将C语言代码和C++语言进行分离编译,再统一链接。
第二章语言可用性的强化
变量/常量/流程
nullptr
nullptr的是替代NULL,C++不允许将void *隐式转换到其他类型。
void foo(char *);
void foo(int);
//直接调用将会调用void foo(int);;这违反常理
foo(NULL);所有的空指针一律使用nullptr,而不要用NULL。
constexpr
修饰变量,const并未区分编译器常量和运行期常量,constexpr限定编译器常量。
修饰函数,constexpr修饰的函数返回值不一定是编译期常量,这个有点像inline。
只读的语义用const,常量的语义用constexpr。
if/switch变量声明强化
C++中可以将变量声名放在if和switch中,作用于就从函数下降到本身的作用域中。
if (int a = f(); a != 1) {
// 代码块A
cout << a << endl;
} else if (int b = g(); b != 2) {
// 代码块B
a += b;
cout << a << endl;
} else {
// 代码块C
a -= b;
cout << a << endl;
}初始化列表
用initializer_list的构造函数被称为初始化列表构造函数,具有这种构造函数的类型将在初始化时被特殊处理。
结构化绑定
std::tuple<int, double, std::string> f(){
return std::make_tuple(1, 2.3, "456");
}
int main(void){
auto [x, y, z] = f();
std::cout << x << ", " << y << ", " << z << std::endl;
return 0;
}auto,decltype
用于类型推导。
auto:
- 当类型不为引用时,auto 的推导结果将不保留表达式的 const 属性;
- 当类型为引用时,auto 的推导结果将保留表达式的 const 属性;
- auto 关键字不能定义数组。
还有一个尾返回类型(C++11),利用auto关键字将返回类型后置,但是在C++14中,可以让普通函数具备返回值推导:
// C++ 11
template<typename T, typename U>
auto add(T x, U y) -> decltype(x+y){
return x + y;
}
// C++ 14
template<typename T, typename U>
auto add2(T x, U y){
return x + y;
}decltype(auto)
C++ 14开始提供的用法,和直接使用auto相比最大的区别在于这个能够自动识别是否是引用&,auto只能识别到数据类型,demo:
std::string lookup1();
std::string& lookup2();
// C++ 11的封装形式如下:
std::string look_up_string_1(){ return lookup1(); }
std::string& look_up_string_2(){ return lookup2(); }
// C++ 14可以如下:
decltype(auto) look_up_string_1(){ return lookup1(); }
decltype(auto) look_up_string_2(){ return lookup2(); }if constexpr
C++ 17将constexpr关键字引入if判断,在编译期完成判断。
template<typename T>
auto print_type_info(const T& t){
if constexpr(std::istegral<T>::value){
return t + 1;
} else {
return t + 0.001;
}
}
int main() {
std::cout << print_type_info(5) << std::endl;
std::cout << print_type_info(3.14) << std::endl;
}会被编译成这样:
int print_type_info(const int& t){
return t + 1;
}
double print_type_info(const double& t){
return t + 0.001;
}
//...其实这个语法糖…我不太能明白用处,写成两个函数不行吗,可能因为我对模板编程接触实在少。
区间for迭代
像python的for循环,要注意的主要是使用auto想修改的话,需要使用auto &。
std::vector<obj_class> vec;
//...
for(auto &v: vec){
// do sth
}对象/模板
外部模板
传统C++中,模板只有使用时才会被实例化。并且每个编译单元(文件)都会被实例化,这增加了时间,C++11引入了外部模板:
template class std::vector<bool>; // 强制实例化
extern template class std::vector<double>; // 不在当前编译文件中实例化模板类型别名模板
模板和类型是不同的,模板是用来生产类型的。
typedef可以为类型定义一个新的名称,但没法为模板定义一个新名称,因为木板不是类型,C++ 11引入了using解决这个问题。
所以typedef给类型定义别名,using除了typedef能做的,还能够给模板定义别名。
总结一下using的三个用途:
- 引入命名空间
- 指定别名(对比typedef 有两个好处,第一更加清晰,第二可以对模板)
- 在之类中引用基类成员
默认模板参数
template<typename T = int, typename U = int>
auto add(T x, U y){
return x + y;
}变长参数模板
这个好像篡改了语法,所有的关键词后面加上…就变成了这个相关的功能,感觉还挺复杂的,列一下demo:
template<typename... Ts> class Magic; // 其中Ts就是变长模板的“类型名”,可以接受0~n个
template<typename... Args> void printf(const std::string &str, Args... args); // 有类型安全的printf
template<typename... Ts>
void magic(Ts... args){
std::cout << sizeof...(args) << std::endl;
}
// 参数解包,1. 递归模板函数
template<typename T0>
void printf1(T0 value){
std::cout << value << std::endl;
}
template<typename T, typename... Ts>
void printf1(T value, Ts... args){
std::cout << value << std::endl;
printf1(args...);
}
// 参数解包,2. 变参模板展开
template<typename T0, typename... T>
void printf2(T0 t0, T... t){
std::cout << t0 << std::endl;
if constexpr(sizeof...(t) > 0) printf2(t...);
}
// 参数解包,3. 初始化列表展开
template<typename T, typename... Ts>
auto printf3(T value, Ts... args){
std::cout << value << std::endl;
(void) std::initializer_list<T>{([&args]{
std::cout << args << std::endl;
}(), value)...};
}折叠表达式
template<typename... T>
auto sum(T... t){
return (t + ...);
}非类型模板参数推导
template <auto value>
void foo() {
std::cout << value << std::endl;
}
int main() {
foo<10>(); // value被推导为int类型
}委托构造
构造函数可以在同一个类的一个构造函数中调用另一个构造函数。
class Base{
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value): Base() {
value2 = value;
}
};使用委托构造函数,就不能再使用初始化列表构造其他成员了。
继承构造
class Base{
public:
Base();
Base(int);
}:
class SubClass: public Base{
using Base::Base; // 继承构造
};假设一旦使用了继承构造函数,编译器就不会为派生类生成默认构造函数。这样,我们得注意继承构造函数无參版本号是不是有须要。
显示虚函数重载
override显示告诉编译器这个函数是重载虚函数。
final是显示告诉编译器,防止被继承这个函数。
显示禁用默认函数
传统C++中,如果程序员没有提供,编译器会为对象生成默认构造、复制构造、赋值算符以及析构函数,同时也为所有类定义了注入new delete这些运算符。
C++ 11的解决方案:
class Magic {
public:
Magic() = default; // 显式使用编译器生成的构造
Magic& operator=(const Magic&) = delete; // 显示声明拒绝编译器生成构造
Magic(int magic_number);
};强类型枚举
C++ 11引入了枚举类,使用enum class的语法进行声名:
enum class new_enum: unsigned int {
value1,
value2,
value3 = 100,
value4 = 100
};这样的枚举不能被隐式转化为整数,不能与整数进行比较,不能与不同枚举类型的值进行比较。
也解决了传统C++中,同一个命名空间的不同枚举类型的枚举值名字不能相同的问题。
第三章 语言运行期的强化
lambda表达式
值拷贝:被捕获的变量在lambda表达式创建时拷贝,而非调用时才拷贝;
- 引用拷贝:和正常引用无异;
- 隐私捕获:直接填[=]或者[&]让编译器自行推导;
- 表达式捕获:有些变量不允许复制和引用,C++提供了表达式捕获可以进行任意的初始化,让我们可以把这些变量变成右值。
其中当lambda表达式的捕获列表为空时,闭包对象还能够转换为函数指针值进行传递。
using foo = void(int);
void functional(foo f){ f(1); }
int main() {
auto f = [](int value) { std::cout << value << std::endl; };
functional(f);
}泛型lambda
C++ 14支持lambda使用auto作为类型,提供泛型lambda:
auto add = [](auto x, auto y){
return x + y;
}
add(1, 2);
add(1.1, 2.2);std::function
函数的容器,对可调用实体的一种类型安全的包裹(函数指针的调用不是类型安全的)。
std::bind和std::placeholder
- 其中std::placeholder::_1表示bind对象调用时的第一个参数;
- std::bind支持嵌套绑定,如下demo
int foo(int a, int b, int c) { return a + b + c; }
int g(int n) { return n + 2; }
int main(){
auto bindFoo = std::bind(foo, std::placeholders::_1, 1, std::bind(g, 3));
bindFoo(3);
}右值引用
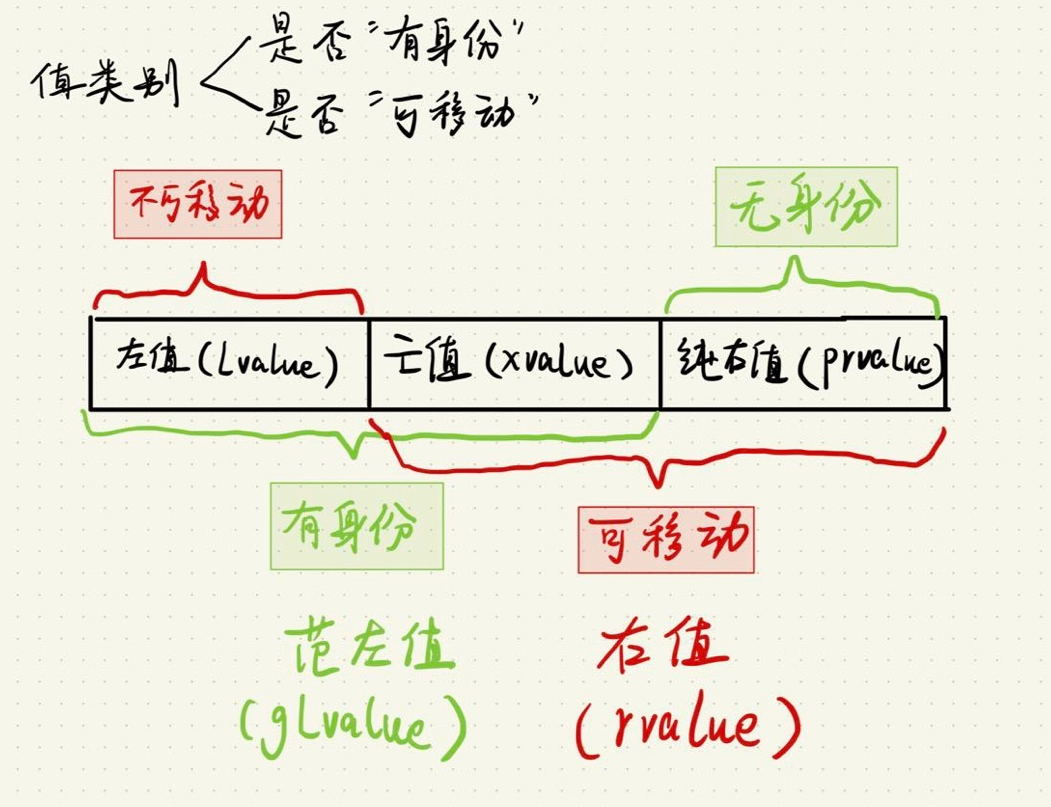
关于左值、右值、将亡值的概念我大概清楚了,但是书中这个例子我没理解清楚:
#include <iostream>
using namespace std;
class ClassA{
public:
int *pointer;
ClassA(): pointer(new int(1)){
cout << " 构造" << pointer << endl;
}
ClassA(ClassA& a): pointer(new int(*a.pointer)){
cout << " 拷贝构造" << pointer << endl;
}
ClassA(ClassA&& a): pointer(a.pointer) {
a.pointer = nullptr;
cout << " 移动" << pointer << endl;
}
~ClassA(){
cout << " 析构" << pointer << endl;
delete pointer;
}
};
ClassA return_rvalue(bool test){
ClassA a, b;
if(test) return a;
else return b;
}
int main(void){
ClassA obj = return_rvalue(false);
cout << "obj: " << endl;
cout << obj.pointer << endl;
cout << *obj.pointer << endl;
}
/* 打印结果如下:
构造0x555b80d39e70
构造0x555b80d3a2a0
移动0x555b80d3a2a0
析构0
析构0x555b80d39e70
obj:
0x555b80d3a2a0
1
析构0x555b80d3a2a0
*/这里我觉得移动构造应该会执行两次才对,return_rvalue从b对象到将亡值一次复制,从将亡值到main函数中的obj一次复制,实在不解为什么只执行了一次,就深入看了一下汇编,便有了本笔记的最后一章。
我不放汇编代码,直接给出看汇编的结论:
main函数在调用return_rvalue函数时,除了传递参数false,还传递了一个8字节的内存地址进去,return_rvalue在返回时并不是创建了一个新的对象返回给上一层,而是直接把b移动给了上一层传进来的对象里。
换句话说,obj内存开辟是在main函数里做的,但拷贝构造函数发生在return_rvalue返回之前。
在这里我还做了几个测试,在C中,当返回的对象内存大于4字节时,返回值是通过调用者提供的内存返回的。C++是的规则好像特殊一点,跟引用和右值有关系。
右值引用
T&& a是一个右值引用,它引用的对象是一个右值,但是它本身是一个左值,可以继续引用其他对象。
移动语义:std::move
会将参数的内容“移动”到左边,参数的对象会被清空。
完美转发
引用坍缩规则:在传统C++中,不能对一个引用类型继续进行引用,但右值引用的出现放宽了这一做法,从而引起坍缩规则。无论模板参数是什么类型的引用,当且仅当实参类型为右引用的时候,模板参数才能被推到位右引用类型。
第四章 容器
std:array
- 相比vector,array大小是固定的,空间消耗可控;
- 相比传统数组,array封装的更加安全。
和C风格的接口兼容时:
void foo(int *p, int len){ return ; }
std::array<int, 4> arr = {1, 2, 3, 4};
// foo(arr, arr.size()); // 非法,无法隐式转换
foo(&arr[0], arr.size());
foo(arr.data(), arr.size());std:forward_list
std::list是双向链表,这个是单向链表,不展开
std::unordered_map, std::unorder_set, std::unordered_multimap, …
std::map和std::set都是用红黑树实现的;
这里unordered_xx都是用hash表实现的;
元组
元组的三个核心函数:
- std::make_tuple: 构造元组
- std::get: 获得元祖某个位置的值
- std::tie: 元祖拆包
auto student = std::make_tuple(1.7, 'D', "张三");
auto lv = std::get<2>(student);
auto score = std::get<1>(student);
double gpa;
char grade;
std::string name;
std::tie(gpa, grade, name) = student;运行期索引
上面的例子中,std::get
C++ 17 引入了variant<>,但用起来还挺复杂的,用到再深究吧。
元组的合并与遍历
std::tuple_cat(student1, student2);可以合并两个元组
遍历需要用到上面variant和元组模板的::value属性。
书里没写,我在这多插嘴一句,元组的实现在底层其实是多个类的继承,所以每个元组类型都是通过变长参数模板+继承来做的,因为继承内存其实非常紧凑,而每个元组本质上是一个对象,每个元组的类的长度是固定的,所以有一个value的静态变量来获取长度。
从这里向下的内容严格来说,只算是库的内容,不算是语言层面的内容了
从这里向下的内容严格来说,只算是库的内容,不算是语言层面的内容了
第五章 智能指针与内存管理
RAII和引用计数
RAII是指在析构函数中释放资源,就不会忘记释放资源了。
引用计数是指,记录对象被引用的次数。
这俩是所有智能指针实现的低层级制。
std::shared_ptr, std::make_shared
引用计数变为0时,对象会被delete。
std::unique_ptr
禁止与其他的智能指针共享一个对象,从而保证代码的安全。
不可复制,但可以移动。
std::weak_ptr
weak_ptr不会引起计数增加
第六章 正则表达式
std::regex
之前一般的解决方案是使用boost的正则表达式库。
C++ 11 将正则表达式引入了标准库的支持。
第七章 并行与并发
线程基础
std::thread 用于创建一个执行的线程实例。
get_id() 可以获得所创建线程的线程ID,使用join() 来等待一个线程结束。
#include <iostream>
#include <thread>
int main() {
std::thread t([](){
std::cout << "hello world." << std::endl;
});
t.join();
return 0;
}互斥量与临界区
std::mutex是最基本的mutex类,实例化可以创建互斥量,然后通过lock()上锁,unlock()解锁。还有一个RAI语法的模板类std::lock_guard和std::unique_lock。
std::unique_lock更自由,可以主动lock和unlock。
std::future
跟python里的future挺像的,通过回调的形式来给予异步线程的返回值。
条件变量
std::condition_variable是为了解决死锁而生,实例被创建主要就是用于唤醒等待线程。std::conditioin_variable的notify_one()用于唤醒一个线程;notify_all()用于唤醒所有线程。
原子操作与内存模型
a=1, b=3; 因为CPU可能乱序,可能导致另外一个线程看到b先为3;
mutex可以解决这个问题,因为mutex是操作系统级别的功能;
同时C++11还引入了std::automic模板,为浮点整数提供了基本的数据成员函数。
一致性模型
当多个线程对一个变量v操作时,每个线程都能感受到v的变化,但对于v而言,表现为顺序执行的程序,v并没有因为引入多线程而得到任何效率上的收益。如何适当加速呢?削弱原子操作在进程间的同步调节。
- 线性一致性;
- 顺序一致性;
- 因果一致性;
- 最终一致性;
内存顺序
为了追求极致的性能,实现各种强度要求的一致性,C++为原子操作定义了六种不同的内存顺序std::memory_order的选项,表达了四种多线程间的同步模型:
- 宽松模型:std::memory_order_relaxed
- 释放/消费模型:std::memory_order_consume, std::memory_order_release
- 释放/获取模型:std::memory_order_acquire, std::memory_order_acq_rel, std::memory_order_release
- 顺序一致模型:std::memroy_order_seq_cst
第八章 其他杂项
long long in
C99就已经引入了,C++ 11中也引入了,至少是一个64位的比特数。
noexcept的修饰和操作
C++11将异常声明简化为以下两种情况,并用noexcept进行限制:
- 函数可能抛出异常;
- 函数不能抛出异常;
noexcept还能做操作符,用于操作一个表达式,无异常时返回true,否则返回false。
noexcept(may_throw())
noexcept(no_throw())noexcept修饰完函数之后,外部不会捕获到异常。
自定义字面量
没想到使用场景,demo:
std::string operator"" _wow1(const char *wow1, size_t len){
return std::string(wow1) + "woooooow, amazing!";
}
std::string operator"" _wow2(unsigned long long i){
return std::to_string(i) + "woooooooooooow, amazing!!";
}
int main(){
auto str = "abc"_wow1;
auto num = 1_wow2;
std::cout << str << std::endl << num << std::endl;
}内存对齐
C++11引入了两个新的关键字alignof和alignas来支持内存对齐进行控制。
alignof类似于sizeof,获取跟平台相关的std::size_t类型的值,用于查询该平台的对齐方式。
alignas用于修饰某个结构的对齐方式。
第九章 展望:C++20简介
诸如Concept/Module/Coroutine/Ranges等特性的提案都蓄势待发。
概念与约束
int main() {
std::list<int> l = {1, 2, 3};
std::sort(l.begin(), l.end());
}上面的例子会产生不可读的编译错误,因为std::sort对排序容器必须提供随机迭代器,但std::list是不支持随机访问的。引入概念之后,我们可以对模板进行约束:
template<typename T>
requires Sortable<T> // Sortable 是一个概念
void sort(T& c);还有模块、合约、范围、协程、事务内存等。
其他部分作者还没写完,就到这吧。
汇编学习
这一部分不是书里的内容,是在学C++右值引用的时候对一些细节不理解,但没找到相关的资料,只能深入汇编去看实现细节,这里也记录一下相关的信息:
ELF文件格式
ELF文件主要有四种类型:
- 可重定位文件(Relocatable File),可以用来和其他目标文件链接,即xx.o文件。
- 可执行文件(Executable File),规定了exec() 如何创建程序的进程印象。
- 共享目标文件(Shared Object File),可以和其他的可重定位文件一起链接成另一个目标文件;链接器可以将它与某个可执行文件组合,创建成可执行文件,即xx.so。
- 内核转储(core dumps),存放当前进程执行上下文,用于dump信号触发。
ELF提供两种视图,分别是链接视图和执行视图:
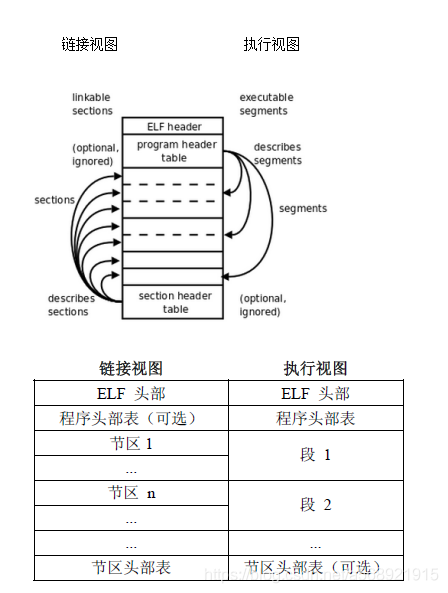
链接视图:以节(section)为单位,在连接时用到的视图。
执行视图:以段(segment)为单位,在执行时用到的视图。
可以这样来理解,在链接时,会将文件的相同的节组成一个段,在执行时把对应的段载入内存即可。
比较重要的一些节:
- .text 代码段
可以通过objdump -d 反汇编查看ELF文件代码段的内容。 - .strtab/.shstrtab 字符串表
所有使用到的字符串都放在这里,以’\0’分隔。 - .symtab 符号表
在链接的过程中需要把多个不同的目标文件合并在一起,不同的目标文件相互之间会引用变量和函数。在链接过程中,我们将函数和变量统称为符号,函数名和变量名就是符号名。
这里的每个符号对应一个地址。 - .eh_frame / .eh_frame_hdr
在调试程序的时候经常需要进行堆栈回溯,早期使用通用寄存器(ebp)来保存每层函数调用的栈帧地址,但局限性很大。后来现代Linux操作系统在LSB(Linux Standard Base)标准中定义了一个.eh_frame section,用来描述如何去unwind the stack。
GAS(GCC Assembler)汇编编译器定义了一组伪指令来协助eh_frame生成调用栈信息CFI(Call Frame Information)。 - 重定位表(.relname)
链接器在处理目标文件时,需要对目标文件中的某些部位进行重定位,即代码段和数据中中那些绝对地址引用的位置。对于每个需要重定位的代码段或数据段,都会有一个相应的重定位表。比如”.rel.text”就是针对”.text”的重定位表,”.rel.data”就是针对”.data”的重定位表。
GOT是全局偏移表( Global Offset Table),用于存储外部符号地址;PLT是程序链接表(Procedure Link Table),用于存储记录定位信息的额外代码。
寄存器
常用寄存器:
EAX:一般用作累加器
EBX:一般用作基址寄存器(Base)
ECX:一般用来计数(Count)
EDX:一般用来存放数据(Data)
ESP:一般用作堆栈指针(Stack Pointer)
EBP:一般用作基址指针(Base Pointer)
ESI:一般用作源变址(Source Index)
EDI:一般用作目标变址(Destinatin Index)
其中esp是栈顶,但是低地址;ebp是栈底,是高地址。
关于x86平台寄存器使用的一些约定:
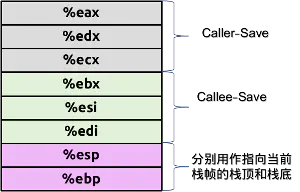
- 当该函数是处于调用者角色时,如果该函数执行过程中产生的临时数据会已存储在%eax,%edx,%ecx这些寄存器中,那么在其执行call指令之前会将这些寄存器的数据写入其栈帧内指定的内存区域,这个过程叫做调用者保存约定(英文原名称:Caller Save)。
- 当该函数是处于被调用者角色时,那么在其使用这些寄存器%ebx,%esp,%edi之前,那么该函数会保存这些寄存器中的信息到其栈帧指定的内存区域,这个过程叫被调用者保存约定。
- %eax总会被用作返回整数值。
- %esp,%ebp总被分别用着指向当前栈帧的顶部和底部,主要用于在当前函数推出时,将他们还原为原始值
X86_64平台的约定
相比于寄存器而言,存储器的访问太慢了,因为X86_64有16个通用寄存器,当函数调用时少于6个参数是直接通过寄存器来存储参数的,多于6个还是依然通过入栈实现。
所以需要注意两点:
- 为了效率,函数参数尽量少于6个;
- 寄存器只有64位,传递较大参数时,尽量使用指针。
帧栈原理
32位帧栈:

主要依靠的汇编指令:call和ret。前者跳转到函数入口执行,后者处理函数返回。
call _func做了两件事:
- pushl %eip // 保存下一条指令的地址,用于函数返回继续执行
- jmp _func // 跳转到函数_func
ret指令的作用相当于
- popl %eip // 将栈中的地址复制到eip寄存器中,返回前一个函数的上下文执行
leave指令相当于下面两条:
- moveq %rbp, %rsp // 将现在的栈底赋值给栈顶
- popq %rbp // 将前一个栈底弹出
x86_64帧栈
通常情况下,x86_64函数简化了帧栈,不再将x86中的%rbp寄存器作为栈底寄存器,只是用%rsp记录当前栈顶。唯一写入栈的操作就是执行到call时会push返回地址 8字节,但是以下情况需要用到帧栈:
- 局部变量太多,64位寄存器处理不过来;
- 局部变量中存在数组或者结构体(或者叫做类类型)的变量;
- 使用取址操作符&就计算局部变量的的内存地址;
- 调用另外一个超过6个参数的函数;
- 需要在修改它们之前保存被调用者保存寄存器的状态;
栈回溯
在早期技术中,栈回溯是通过(%ebp)获得上一个栈的地址,再对上一个地址取值就是上上个地址;但现代Linux放弃了这个技术,节省出了一个ebp寄存器,原有的栈调用被放在eh_frame这个专用于存储栈回溯相关的段中。
CFI伪指令生成在汇编文件中,根据链接选项(是否开启debug以及是否使用eh_frame段)来确定指令的执行内容,形式如下:
cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset ebp, -8CFI(calling frame info)的作用是出现异常时stack的回滚(unwind),回滚的过程是一级级CFA往上回退,直到异常被catch。
其中eh_frame是编译完就静态生成好的,这个点困扰了我好久,现在大概理解了回溯的要点,eh_frame是根据汇编代码生成的一张表,运行时汇编对cfi的修改实际上就是在改动eh_frame中的索引。
引用:
https://zhuanlan.zhihu.com/p/286088470
https://blog.csdn.net/a568921915/article/details/103427976
https://zhuanlan.zhihu.com/p/288636064
https://stackoverflow.com/questions/7534420/gas-explanation-of-cfi-def-cfa-offset
https://www.jianshu.com/p/e7e21a51093e