主题
在当python的函数越短,通常意味着性能越高!
这不是笑话,在不改变算法的情况下,同一个功能是一定存在一个最短指令集的,当python代码变短意味着指令码变少,那多的指令码就在底层以CPU指令码的形式转移了。
这叫做同算法指令集数量守恒。 ——本人
第二章 通过性能分析找到瓶颈
python可用的分析工具:
- cProfile:自带的运行分析工具,可以计算函数的执行次数和时间;
- runsnakerun: 可视化cProfile的内容;
- link_profile: 分析的更加细致,但是执行效率会变慢,要增加修饰符;
- memory_profiler:诊断内存的用量
- heapy:调查堆上的对象
- dis模块:生成CPython字节码
heapy模块
- guppy.hpy() – 获得heapy对象,作为操作接口。
- heap() – 获得堆中的可见对象(reachable and visible),这些对象并不包含guppy库使用和创建的对象。
- setref() – 设置一个参考点,下一次调用heap()函数会计算这个参考点之后创建的。
- heapu() – 获得不可见(循环引用)的对象的状态和列表,heapu()返回一个状态(guppy.heapy.Part.Stat)标明不可见对象。
dis模块
获得python的字节码
def myfunc(alist):
return len(alist)
>>> dis.dis(myfunc)
2 0 LOAD_GLOBAL 0 (len)
3 LOAD_FAST 0 (alist)
6 CALL_FUNCTION 1
9 RETURN_VALUE
>>> import math
>>> def myfunc(x):
... return math.sin(x)
...
>>> import dis
>>> dis.dis(myfunc)
2 0 LOAD_GLOBAL 0 (math)
2 LOAD_ATTR 1 (sin)
4 LOAD_FAST 0 (x)
6 CALL_FUNCTION 1
8 RETURN_VALUE
>>> from math import sin
>>> def myfunc(x):
... return sin(x)
...
>>> dis.dis(myfunc)
2 0 LOAD_GLOBAL 0 (sin)
2 LOAD_FAST 0 (x)
4 CALL_FUNCTION 1
6 RETURN_VALUE默认值不能用可变类型
>>> def B():
... def A(x=[]):
... x.append(2)
... return x
... return A
...
>>> import dis
>>> dis.dis(B)
2 0 BUILD_LIST 0
2 BUILD_TUPLE 1
4 LOAD_CONST 1 (<code object A at 0x7febe7e5de40, file "<stdin>", line 2>)
6 LOAD_CONST 2 ('B.<locals>.A')
8 MAKE_FUNCTION 1
10 STORE_FAST 0 (A)
5 12 LOAD_FAST 0 (A)
14 RETURN_VALUE
构建了一个函数,是B.<locals>.A,并且list作为默认值一开始就存进去了
>>> def X(x=[]):
... return x
...
>>> X.__defaults__
([],)第三章 列表和元祖
python使用魔法函数eq和lt来进行对象的比较。
bisect模块是二分查找模块
通用代码会比某个特定问题设计的代码慢很多。
blist是比默认的list在存在大量修改的list场景下实现更快的数据结构。
第四章 字典和集合
python在va == vb的判断内部调用的是eq方法。
可以被散列(哈希)的对象是同时实现了hash的魔法函数以及eq或者cmp两者之一的类型。
这里一定要实现eq或者cmp为了防止两个对象的hash相同,那样就需要判断两个对象是否相等,如果相等则是同一个,不然则是不同的。
python对dict本质就是一个hash表,底层对hash冲突的处理方式是开放寻址法
同时在python的dict到达容量的2/3时会发生扩容,扩容的复杂度是O(n)的,需要将所有的对象都重新hash一次。
每当python访问一个变量、函数或模块时,首先会查找locals()数组,其内保存了所有本地变量的条目,如果不在本地变量里那么搜索globals()字典,最后如果对象也不在则搜索builtin对象。这里可能为了搜一个函数或者变量要搜好几个dict。
第五章 迭代器和生成器
代码每次运行到yield该函数就会“发射”出一个值,然后外部代码需求另一个值时该函数才会继续运行(上下文会保存)。
使用python的内置函数iter来创建迭代器,iter函数会返回对象的iter属性:
# python的循环
for i in object:
do_work(i)
# 等价于
object_iterator = iter(object)
while 1:
try:
i = object_iterator.next()
do_work(i)
except StopIteration:
break如果只是计算满足某个条件的列表数量,这样可以节省一笔内存
# 不要写:
[i for i in xrange(n) if i % 3 == 0]
# 要用:
sum((1 for i in xrange(n) if i % 3 == 0))
----------------------
项目里一些代码的鞭尸:
level_aver = float(sum([member.rank_level for member in self.member_dict.values()])) / self.size
total_num = sum([abs(value) for value in pop_result.itervalues()])
sum([mgr.busy_count for mgr in self.combat_mgr.itervalues()])
# 这里每次+可能会增加一次内存分配和复制
# 用list(chain()) 在1000*1000的对象上操作要快396倍
task_list = reduce(lambda x, y: x + y, task_level_list)
# 而且原场景其实不需要这个list,拼接了之后只是一次性使用直接返回迭代器即可python里一些表达式:
- 列表表达式: [f(xx) for xx in rr if xx else f(xx)]
- 生成器表达式: (f(xx) for xx in rr if xx else f(xx))
- 字典表达式: { key_expr: value_expr for value in collection if condition }
- 集合生成器: {f(xx) for xx in rr if xx else f(xx)}
在这里记录一下。
标准库中的itertools库提供了内建函数map, reduce, filter和zip的生成器版本(分别是imap, ireduce, ifilter和izip),以及其他很多有用的函数,特别是:
- islice 允许对一个无穷生成器进行切片
- chain 讲多个生成器链接到一起
- takewhile 给生成器添加一个终止条件
- cycle 通过不断重复将一个有限生成器变成无穷
顺便记录一下上面几个函数的功能:
- map(function, iterable, …): 将参数以函数执行的生成器
- reduce(function, iterable[, initializer]): 跟map类似,不过f的参数是两个,先对迭代器中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
- filter(function, iterable): 对迭代器的对象执行f来进行过滤,为True才会返回
- zip([iterable, …]): 将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
- any(iterable), 如果 iterable 的任一元素为真值则返回 True。
- all(iterable), 如果 iterable 的所有元素都为真值则返回 True。
第六章 矩阵和矢量计算
原生python并不支持矢量操作,主要的核心原因是python的列结构存储的内容是指向对象的指针,其次python的字节码没有对矢量操作做优化。
result = 0
for i xrange(num_iterations):
result += i * sin(num_iterations)
return result
# 下面这个快过上面那个,虽然是废话,但是很实用
result = 0
for i xrange(num_iterations):
result += i
return result * sin(num_iterations)
# -------------------------------------
# damage_system
for ratio in reduce_ratio_list:
damage *= ratio
# 比上面要快16%
damage = reduce(operator.mul, reduce_ratio_list, damage)
# -------------------------------------书中用numpy去优化一段代码,带来了40倍的效率提升,但是神奇的事情是,禁用矢量指令集优化,性能依然有极大的提高,用perf分析发现矢量操作近带来了40倍中的15%,剩下的是内存问题导致的效率低下。
perf是一个进程级别的分析工具。
numexpr
将python能够分析执行顺序,非常大程度的优化矩阵,可以自动地利用多CPU的优势,并且考虑到CPU缓存的问题,会特意移动数据让各级CPU缓存拥有正确的数据。
如果numpy可以将速度快几倍,那使用numexpr可能可以将速度提升至几十上百倍。
但是如果矩阵特别小,会有负优化的效果。
第七章 编译成C
Cython、Shed Skin和Pythran是纯粹的基于C的编译方式,凭借Numba的基于LLVM的编译方式,还有替代虚拟机的pypy,内置了一个即时编译器(JIT)。
无论使用哪条路线,都要在适用性和团队效率上作出权衡,
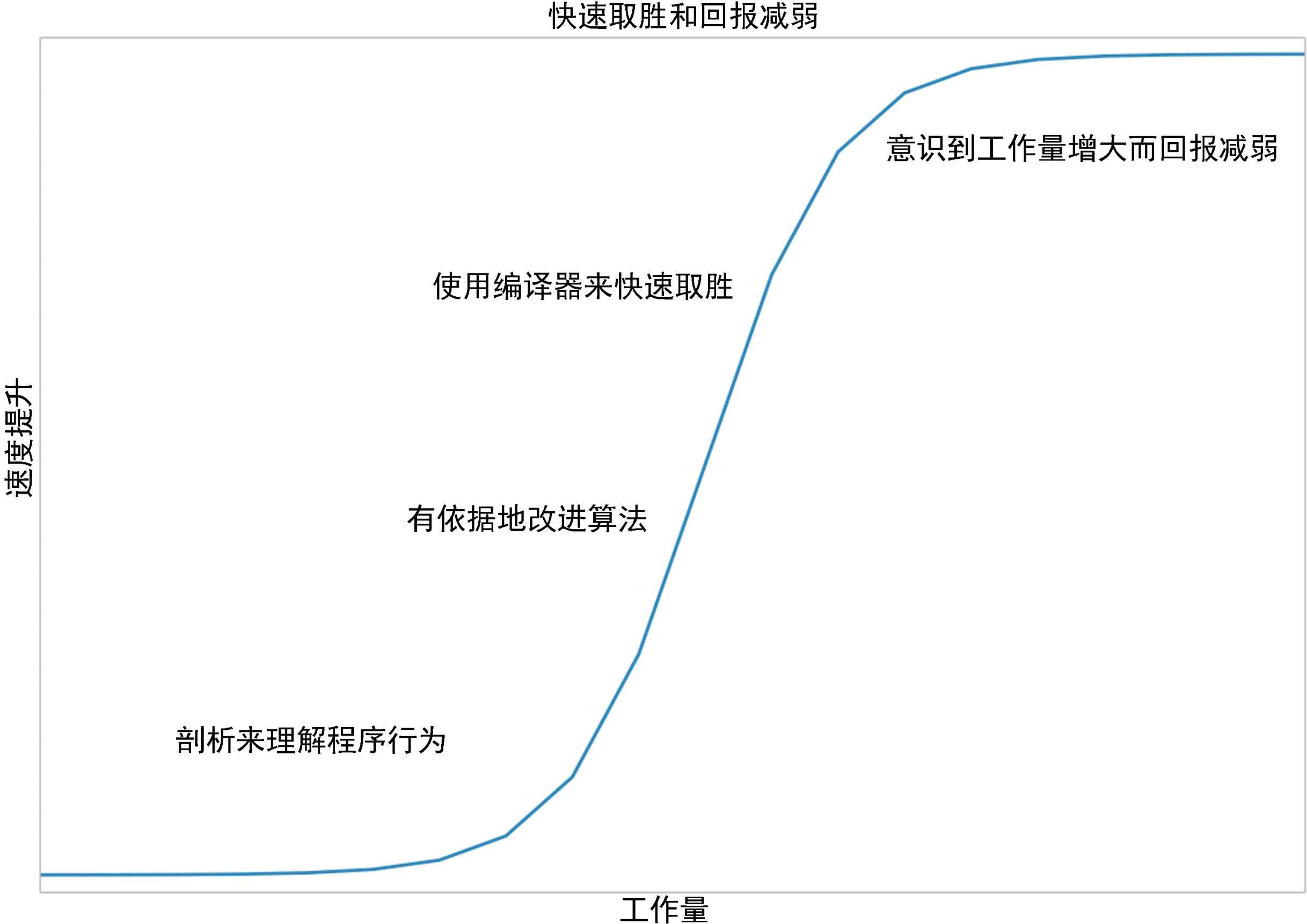
优化是永无止尽的,但是对一个模块的优化是有限的。
顺便一提,pyc只是py编译成的python机器码,并不包含优化。
对python的优化
Cython
可以直接把python代码编译成so,可以先用Cython在服务端优化一轮,顺便提前把模块化做好。
Shed Skin
将python翻译成C++的编译器,会自动去猜测类型,可以直接被import,不像Cython需要显式指定类型。
Shed Skin会将python的list拷贝成Shed Skin环境的变量,这个是会花时间的,
numba
llvm编译器的python脚本编译,只需要在需要编译的函数增加@jit()修饰符即可,执行速度非常快
Pythran
有点像Numba和Cython——我注解函数的参数,接着它接管进一步的类型注解和代码特化,它会利用OpenMP的并行化可能性。
pypy
底层换了虚拟机,提供了JIT,执行时编译,所以第一次会很慢,编译好之后再执行非常快!
pypy和CPython的垃圾回收机制不同。
任何纯python的库pypy都能直接安装运行,但是有C扩展库的就可能无法工作。
内存消耗比cpython多。
写C/C++程序的优化
ctypes
C++只写一些函数,然后通过ctypes来”import”进python,需要在python层将所有的调用对象都转化成ctypes对应的C类型,然后执行。
这里在使用list或者dict的时候,会非常非常消耗。
cffi
相比ctypes方便很多,并且支持一些很便利的语法糖。
CPython模块
我们项目里目前是用的模块,会很繁琐,很简单的代码也要写几十行来兼容,但是好处是控制颗粒度非常高,从无视GIL到引用计数,一切都可以直接去修改,但是对程序的要求也会高一点,因为需要了解python的一些细节。
在大部分情况下,书中的建议是不使用这种方式。
第八章 并发
时间循环有两种方式:回调或者future。
回调会带来很长的调用链,future+asyncio是一个很好的,不过我们用python2是永远没机会用了。
分别使用了gevent,tomado和asyncio
第九章 multiprocessing模块
可以让程序基于进程和线程的并行处理,multiprocessing.Pool的功能感觉很强!
对于使用这个模块,需要解决的问题:
- 把工作拆分成独立的工作单元
- 考虑是否能随机化工作序列
- 尽量让同时在处理的任务数量和CPU数量相同
第十章 集群和工作队列
一个容易调适的系统可能胜过一个更快的系统。
- 启动组件:cron任务,Circus或supervisord
- 测试容灾的组件:ChaosMonkey
- 部署系统:Fabric、Salt、Chef或Puppet
下面几个都是集群化的方案
Parallel Python模块
- 几乎没有依赖性,接口简单;
- 不是很强大,缺少通信机制
Ipython Parallel
IPython作为shell做并行任务控制,依赖ZeroMQ。
NSQ
是一个可随时投入生产的队列系统,有持久性和扩展性。
其他集群化的工具
- Celery
- Gearman
- PyRes
- 亚马逊的简单队列服务(SQS)
第十一章 使用更少的RAM
基础对象开销高:100000000项的list要消耗760MB的内存,可以替换成array,array是连续的内存块,而且array可以直接传递给C++层不需要额外的转换。
python3对字符串的存储效率相比python2提高了很多。
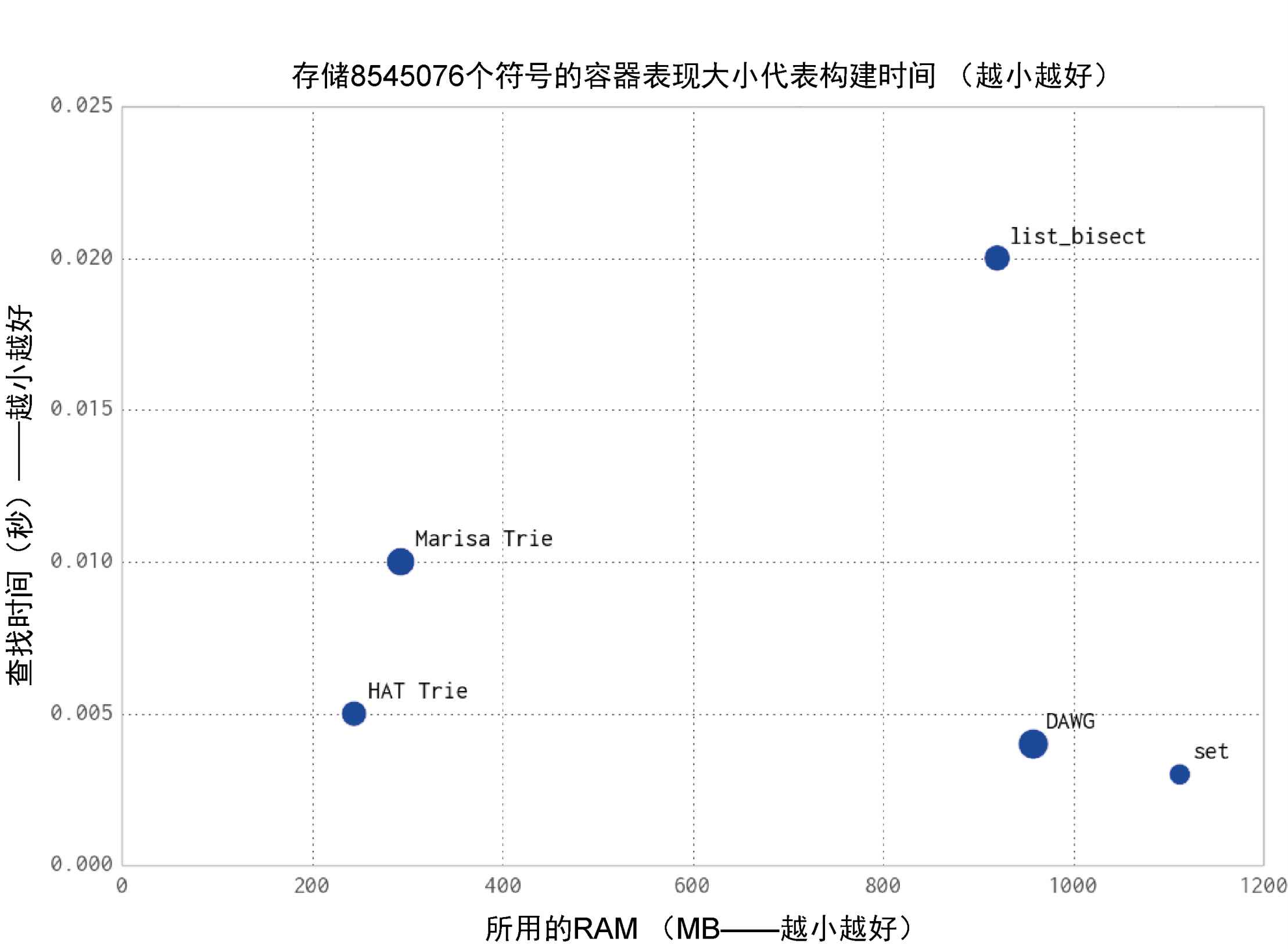
高效地存储文本,trie树和有向无环图 (DAWG)(双trie树结构)单词图:
通过允许概率误差来减少数据集需要的内存空间:
- Morris计数器
- 布隆过滤器
- loglog计数器
End.